The OWASP Top Ten
Welcome to the OWASP Top Ten supplemental site.
This is where you can learn about how the Top Ten is built.
This site is managed by the Top Ten core team in conjunction with the OWASP project site and GitHub repository.
The OWASP Top Ten is a standard awareness document for developers and web application security. It represents a broad consensus about the most critical security risks to web applications. It was started in 2003 to help organizations and developer with a starting point for secure development. Over the years it's grown into a pseudo standard that is used as a baseline for compliance, education, and vendor tools.
Current project status as of Sept 2025
We are planning to announce the release of the OWASP Top 10:2025 at the OWASP Global AppSec Conf in DC the first week of Nov 2025.
The OWASP Top Ten Community Survey is active, please provide your input!
Data Collection (Now - Nov 2025)
Community Survey (Open)
Data Normalization (Complete)
Review Process (In-progress)
Documentation Updates (In-progress)
International Translations
The latest information and call for action

It's time to get machinery running again and figure out what the next OWASP Top Ten is going to look like for 2024. The last two cycles have worked out well for us, so we are going to continue to use the same process for data collection and the same templates as the 2021 collection process. You can find more details in Github or in the README folder behind the bit.ly link which points to a SharePoint folder that will automatically move submissions to Azure blob storage for processing. Templates: https://github.com/OWASP/Top10/tree/master/2024/Data Contribution Process There are a few ways that data can be contributed: Email a CSV/Excel/JSON file with the dataset(s) to brian.glas@owasp.org Upload a CSV/Excel/JSON file to https://bit.ly/OWASPTop10Data Contribution Period We plan to accept contributions to the Top 10 2024 during Jun-Dec of 2024 for data dating from 2021 to current. Data Structure We have both CSV and JSON templates to aid in normalizing contributions: https://github.com/OWASP/Top10/tree/master/2024/Data The following data elements are *required or optional: Per DataSet: Contributor Name (org or anon) Contributor Contact Email Time period (2023, 2022, 2021) *Number of applications tested *CWEs w/ number of applications found in Type of testing (TaH, HaT, Tools) Primary Language (code) Geographic Region (Global, North America, EU, Asia, other) Primary Industry (Multiple, Financial, Industrial, Software, ??) Whether or not data contains retests or the same applications multiple times (T/F) If a contributor has two types of datasets, one from HaT and one from TaH sources, then it is recommended to submit them as two separate datasets. Analysis We will conduct analysis of the data, in a similar manner as the 2021 and hope to also include some trending data over both the 2021 and 2024 collection time periods. Timeline Data Collection: Jun - Dec Analysis: Early 2025 Draft: Early 2025 Release: First half of 2025
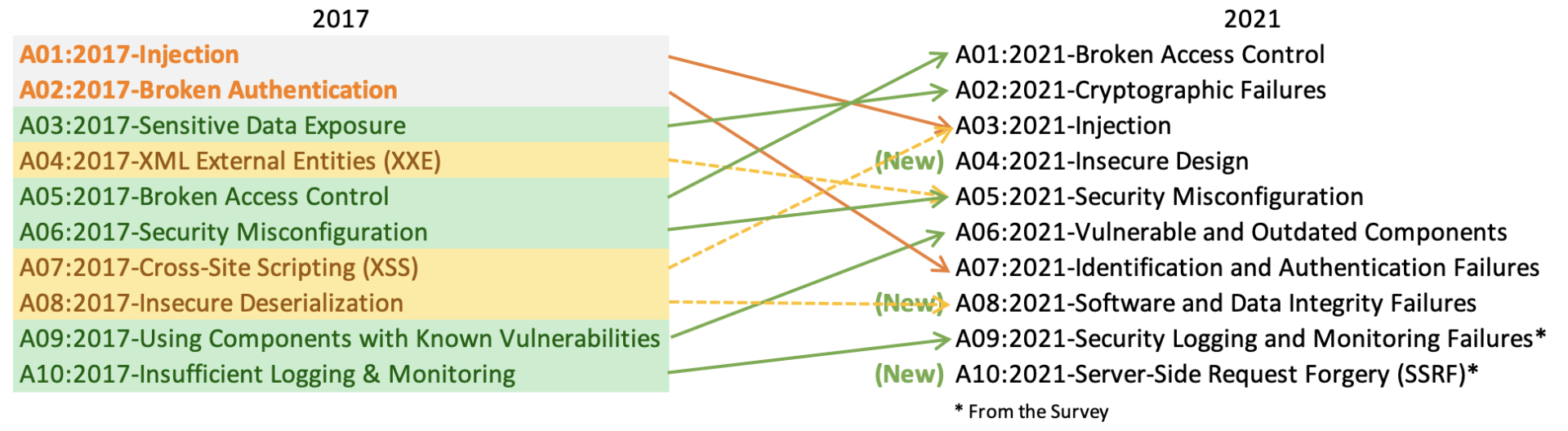
The draft release of the OWASP Top 10 2021 has been published for review: https://owasp.org/Top10 Feedback, comments, issues can all be filed in our GitHub project: https://github.com/OWASP/Top10/issues A mammoth THANK YOU to everyone that contributed data, time, thoughts, and anything else. Hundreds of hours went into the data collection, analysis, and initial draft. Here is a high level overview of what is in the draft. What's changed in the Top 10 for 2021 There are three new categories, four categories with naming and scoping changes, and some consolidation in the Top 10 for 2021. A01:2021-Broken Access Control moves up from the fifth position; 94% of applications were tested for some form of broken access control. The 34 CWEs mapped to Broken Access Control had more occurrences in applications than any other category. A02:2021-Cryptographic Failures shifts up one position to #2, previously known as Sensitive Data Exposure, which was broad symptom rather than a root cause. The renewed focus here is on failures related to cryptography which often leads to sensitive data exposure or system compromise. A03:2021-Injection slides down to the third position. 94% of the applications were tested for some form of injection, and the 33 CWEs mapped into this category have the second most occurrences in applications. Cross-site Scripting is now part of this category in this edition. A04:2021-Insecure Design is a new category for 2021, with a focus on risks related to design flaws. If we genuinely want to "move left" as an industry, it calls for more use of threat modeling, secure design patterns and principles, and reference architectures. A05:2021-Security Misconfiguration moves up from #6 in the previous edition; 90% of applications were tested for some form of misconfiguration. With more shifts into highly configurable software, it's not surprising to see this category move up. The former category for XML External Entities (XXE) is now part of this category. A06:2021-Vulnerable and Outdated Components was previously titled Using Components with Known Vulnerabilities and is #2 in the industry survey, but also had enough data to make the Top 10 via data analysis. This category moves up from #9 in 2017 and is a known issue that we struggle to test and assess risk. It is the only category not to have any CVEs mapped to the included CWEs, so a default exploit and impact weights of 5.0 are factored into their scores. A07:2021-Identification and Authentication Failures was previously Broken Authentication and is sliding down from the second position, and now includes CWEs that are more related to identification failures. This category is still an integral part of the Top 10, but the increased availability of standardized frameworks seems to be helping. A08:2021-Software and Data Integrity Failures is a new category for 2021, focusing on making assumptions related to software updates, critical data, and CI/CD pipelines without verifying integrity. One of the highest weighted impacts from CVE/CVSS data mapped to the 10 CWEs in this category. Insecure Deserialization from 2017 is now a part of this larger category. A09:2021-Security Logging and Monitoring Failures was previously Insufficient Logging & Monitoring and is added from the industry survey (#3), moving up from #10 previously. This category is expanded to include more types of failures, is challenging to test for, and isn't well represented in the CVE/CVSS data. However, failures in this category can directly impact visibility, incident alerting, and forensics. A10:2021-Server-Side Request Forgery is added from the industry survey (#1). The data shows a relatively low incidence rate with above average testing coverage, along with above-average ratings for Exploit and Impact potential. This category represents the scenario where the industry professionals are telling us this is important, even though it's not illustrated in the data at this time. We will be accepting feedback as long as we can and plan to release the final version as part of the OWASP 20th Anniversary on September 24, 2021.

All told for the data collection; we have thirteen contributors and a grand total of 515k applications represented as non-retests (we have additional data marked as retest, so it's not in the initial data for building the Top 10, but will be used to look at trends and such later). We asked ourselves whether we wanted to go with a single CWE for each "category" in the OWASP Top 10. Based on the contributed data, this is what it could have looked something like: 1. Reachable Assertion 2. Divide by Zero 3. Insufficient Transport Layer Encryption 4. Clickjacking 5. Known Vulns 6. Deployment of the Wrong Handler 7. Infinite Loop 8. Known Vulns 9. File or Dir Externally Accessible 10. Missing Release of Resources And that is why we aren't doing single CWEs from this data. It's not helpful for awareness, training, baselines, etc. So we confirmed that we are building risk categories of groups of related CWEs. As we categorized CWEs, we ran into a decision point, focusing more on Root Cause or Symptom ? For example, Sensitive Data Exposure is a symptom, and Cryptographic Failure is a root cause. Cryptographic Failure can likely lead to Sensitive Data Exposure, but not the other way around. Another way to think about it is a sore arm is a symptom; a broken bone is the root cause for the soreness. Grouping by Root Cause or Symptom isn't a new concept, but we wanted to call it out. Within the CWE hierarchy, there is a mix of Root Cause and Symptom weaknesses. After much thought, we focused on mapping primarily to Root Cause categories as possible, understanding that sometimes it's just going to be a Symptom category because it isn't classified by root cause in the data. A benefit of grouping by Root Cause is that it can help with identification and remediation as well. We spent a few months grouping and regrouping CWEs by categories and finally stopped. We could have kept going but needed to stop at some point. We have ten categories with an average of almost 20 CWEs per category. The smallest category has one CWE, and the largest category has 40 CWEs. We've received positive feedback related to grouping like this as it can make it easier for training and awareness programs to focus on CWEs that impact a targeted language or framework. Previously we had some Top 10 categories that simply no longer existed in some languages or frameworks, and that would make training a little awkward. Finding Impact (via Exploit and Impact in CVSS) In 2017, once we defined Likelihood using incidence rate from the data, we spent a good while discussing the high-level values for Exploitability , Detectability , and Technical Impact . While four of us used decades of experience to agree, we wanted to see if it could be more data-driven this time around. (We also decided that we couldn't get Detectability from data so we are not going to use it for this iteration.) We downloaded OWASP Dependency Check and extracted the CVSS Exploit and Impact scores grouped by related CWEs. It took a fair bit of research and effort as all the CVEs have CVSSv2 scores, but there are flaws in CVSSv2 that CVSSv3 should address. After a certain point in time, all CVEs are assigned a CVSSv3 score as well. Additionally, the scoring ranges and formulas were updated between CVSSv2 and CVSSv3. In CVSSv2, both Exploit and Impact could be up to 10.0, but the formula would knock them down to 60% for Exploit and 40% for Impact. In CVSSv3, the theoretical max was limited to 6.0 for Exploit and 4.0 for Impact. We analyzed the average scores for CVSSv3 after the changes to weighting are factored in; and the Impact scoring shifted higher, almost a point and a half on average, and exploitability moved nearly half a point lower on average. There are 125k records of a CVE mapped to a CWE in the NVD data extracted from OWASP Dependency Check at the time of extract, and there are 241 unique CWEs mapped to a CVE. 62k CWE maps have a CVSSv3 score, which is approximately half of the population in the data set. For the Top Ten, we calculated average exploit and impact scores in the following manner. We grouped all the CVEs with CVSS scores by CWE and weighted both exploit and impact scored by the percentage of the population that had CVSSv3 + the remaining population of CVSSv2 scores to get an overall average. We mapped these averages to the CWEs in the dataset as Exploit and Impact scoring for the other half of the risk equation. We agreed that we would use the high watermark of the incidence rate for each grouping to help set the order of the 2021 Top 10. The results of this will be released shortly as our target release date is Sept 24, 2021, to align with the OWASP 20th Anniversary.

We wanted to send everyone updates on our progress related to data analysis, survey, and format of the OWASP Top Ten 2021.

As we're putting together the survey for the next Top Ten so that you can help pick two vulnerability categories or risks for inclusion, we face the challenge of what to include in the survey.